
Join 200+ CIOs, CDOs, Directors, and decision-makers as we unpack how AI is truly transforming
our industries—not through buzzwords or headlines, but through hard science.
As an engineering-led consultancy, we go deep into the research and bring it back
to real-world applications we see today in Oil & Gas,
Utilities, Supply Chain and critical industries.
1. Introduction:
In 2025, AI’s biggest constraint isn’t talent or ideas—it’s resources. Compute budgets are finite. Energy grids are strained. And yet, the problems we want to solve—climate resilience, energy optimization, logistics automation—keep growing.
The issue? Too many teams are still throwing oversized models at under-specified problems. We’ve seen transformer stacks the size of small countries built just to forecast sensor drift or route a package.
We need architectures that match compute to task complexity, not ones that brute-force everything with 175 billion parameters.
Enter Mixture of Experts.
MoE models activate only the components relevant to each input—specialized “experts” that enable efficient, task-specific computation. It’s not a workaround—it’s a smarter paradigm. Don’t run the whole factory when one robot arm will do.
And no—it’s not rocket science. The idea has been around since the '90s. It just got buried under a decade of "bigger is better" thinking. MoE is a reminder that smarter routing beats brute force.
In this edition, Kyle Edwards (Co-founder SERIOUS AI) and Deepak Jhnaji (Senior Engineer) reminds us that not all parts of a model need to be awake all the time. And that scalable AI doesn’t have to mean wasteful AI.
This is Kyle and Deepak,
Mixture of Experts (MoE) is a neural network architecture that activates only a small subset of specialized sub-models—called “experts”—for each input, enabling efficient, task-specific computation at scale.
It’s a way to build:
- Models that are powerful — but don’t cost a fortune to run.
- Systems that are adaptable — but still interpretable.
- Architectures that perform better — while using less energy.
In economic terms, it’s Pareto-efficient AI: better outcomes without paying more — accuracy without latency, scale without waste, specialization without retraining.
MoE lets us build:
- Models that are powerful — but don’t cost a fortune to run.
- Systems that are adaptable — but still interpretable.
- Architectures that perform better — while using less energy.
2. Pareto-Efficient Architectures: A Visual Model
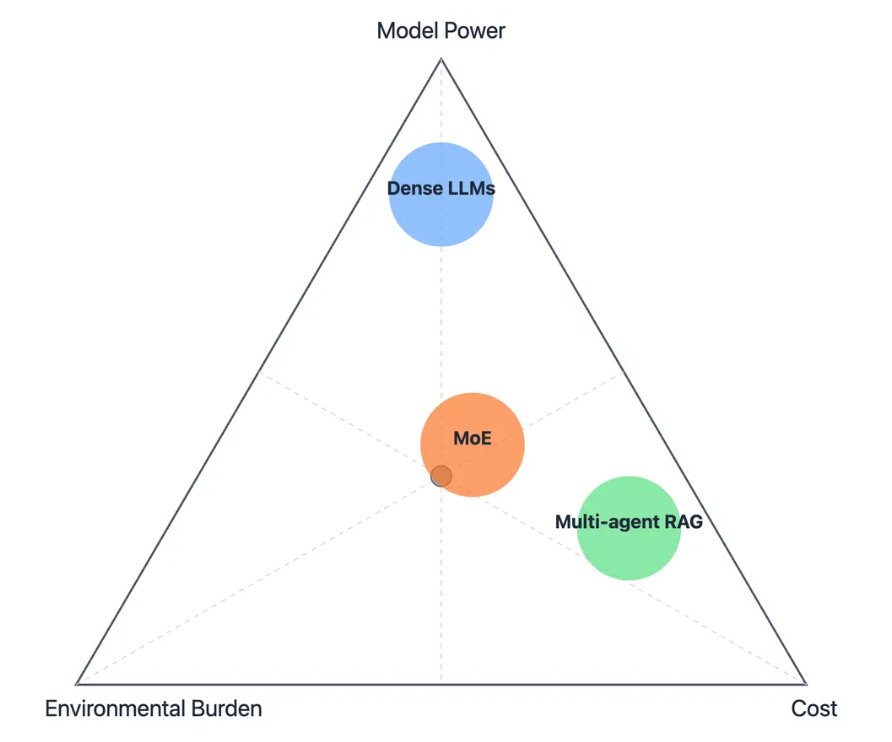
The optimal tradeoff point (gray dot) represents the theoretical perfect balance between all three factors. Mixture of Experts (MoE) architectures achieve a balanced optimization that closely approaches this ideal tradeoff point, with a slight advantage in both model power and cost efficiency.
Architecture Types & Key Tradeoffs:
🔵 Dense LLMs:
High power, high environmental impact. Generally high computational demands, but implementations vary widely in efficiency.
🟢 Multi-agent RAG:
Domain-specialized, business aligned. Typically strong on domain-specific tasks through knowledge retrieval, with costs depending on implementation complexity.
🟠 Mixture of Experts (MoE):
Balanced, conditional computation. Often achieves better efficiency through conditional activation, with improved business alignment through specialized routing.
Dense LLMs live near the top—powerful, but heavy. Multi-agent RAG lives on the bottom right—super aligned, but slower and expensive. MoE sits closer to the middle, achieving strong performance, lower emissions, and excellent domain fit.
In other words: it doesn’t try to do everything, but it does exactly what’s needed—and nothing more.
3. How MoE Works (for Engineers and Curious Humans Alike)
Let’s start with the core equation:
y = ∑ᵢ=1ⁿ G(x)ᵢ ⋅ Eᵢ(x)
Where:
- Eᵢ(x): The i-th expert, a small model trained to do one thing really well.
- G(x)ᵢ: The gating function, which decides which experts to use for a given input.
Only the top k experts are activated per input (usually k = 2). Activating all would defeat the purpose.
This setup gives you:
- Sparse computation: lower cost, faster inference.
- Specialization: each expert gets really good at a subset of tasks.
- Modularity: you can fine-tune or replace experts independently.
Common challenges:
- Expert collapse (one expert does all the work)
- Noisy routing (too random = no benefit)
- Sparse gradients (harder optimization)
Solutions include auxiliary losses, dropout routing, and Gumbel-softmax to stabilize training. Basically, it’s like giving the model training wheels, a map, and a smarter way to make choices along the way.
4. MoE in the Real World: Energy, Oil & Gas, Supply Chain
From energy to oil & gas to supply chains, MoE is delivering these Pareto-efficient gains we’ve been speaking of, here’s some examples that really stick out to us:
Energy Systems
Power grids are messy. Loads change by the second, renewables are volatile, and every watt counts.
- Load Forecasting: MoE-enhanced LSTMs route residential and industrial data to different experts, boosting accuracy by 6–9%.
- Weather-Aware Forecasting: Multi-modal weather data routed to specialized experts improved 72-hour solar/wind predictions by 14%.
- Grid Resilience: Siemens saw 15% faster microgrid response and 22% fewer false positives using MoE-based controllers.
Oil & Gas
The upstream stack is full of signals—seismic, drilling telemetry, environmental sensors.
- Seismic Inversion: Shell reduced interpretation error by 31% using basin-specific MoE experts.
- Drilling Optimization: Schlumberger’s autodrillers used MoE routing on telemetry to cut non-productive time (NPT) by 19%.
- Corrosion Prediction: Chevron achieved 89% F1-score by routing sensor and environmental data through expert modules.
Supply Chain Systems
Dynamic, distributed, and failure-sensitive.
- Inventory Matching: Walmart split data between e-commerce and physical retail streams, reducing stockouts by 27%.
- Supplier Risk: NLP experts parsed contracts, news, and vulnerability databases—improving risk detection accuracy.
- Dynamic Routing: Experts trained on traffic, weather, and time constraints cut fuel use by 12%.
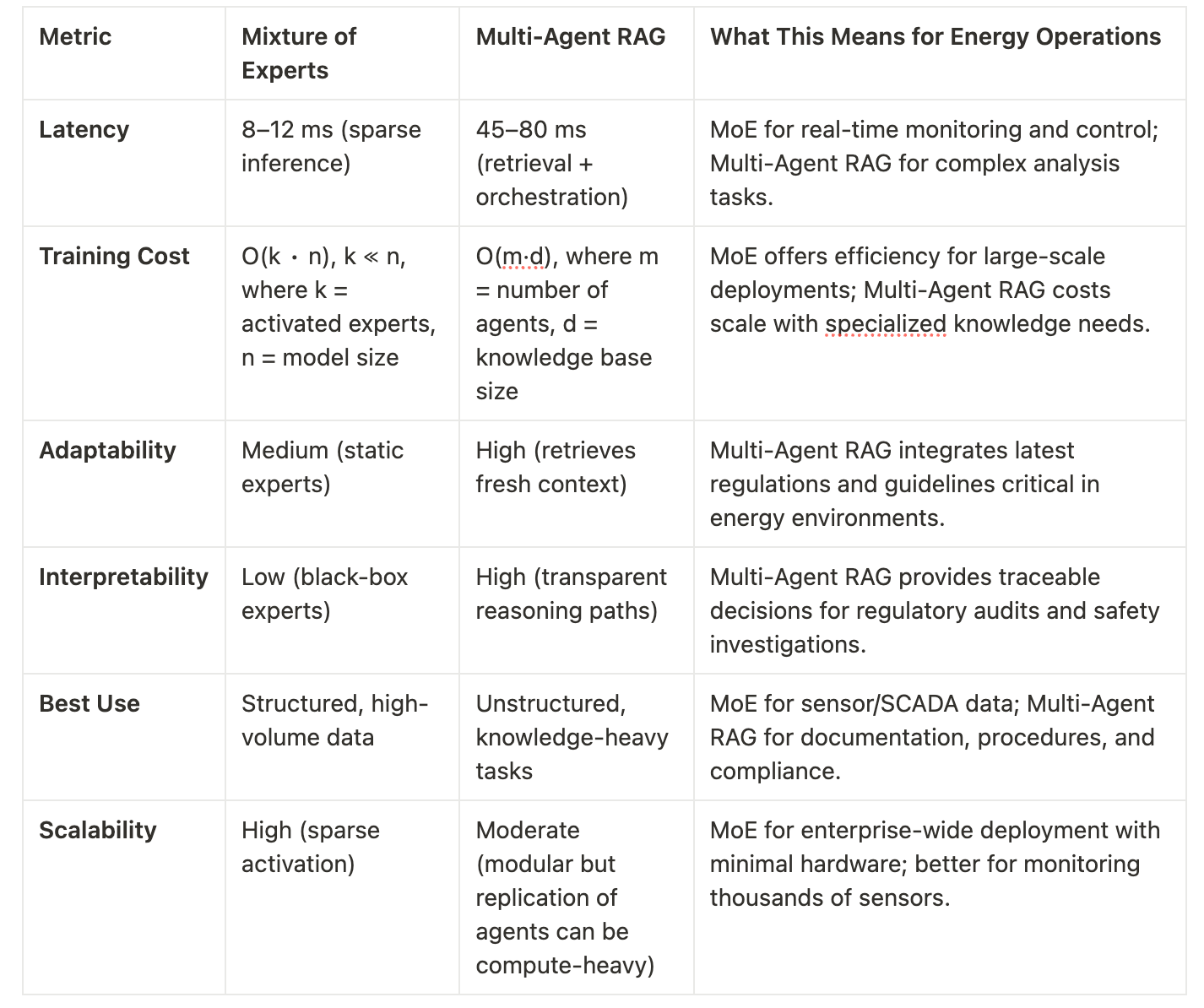
5. MoE vs Multi-Agent RAG: Architecture Cage Match
6. Hybrid Architectures: Best of Both Worlds
Sometimes, you want both efficiency and adaptability. Why not combine them?
- MoE Base Layer: Handles core, structured tasks with sparse computation.
- RAG Overlay: Agents retrieve fresh context—like live weather, commodity prices, or real-time policy updates—to influence expert routing or supplement outputs.
Case Study: BP
Used MoE for seismic modeling. Layered on RAG for real-time pricing and policy feeds. Result: 9% better drilling ROI and GDPR-compliant data integration.
7. Final Words: Architectures That Earn Their Keep
Mixture of Experts isn’t a silver bullet—but it is a fundamentally better hammer. When used right, it gives you:
- Scalability without infrastructure bloat
- Specialization without retraining
- Modularity without orchestration hell
It marks a shift from overbuilt generalists to precise, domain-aligned systems. In sectors like energy, logistics, and industrial automation—where uptime matters and inefficiency costs real money—MoE delivers compute that adapts to complexity, not brute-forces it.
We bring it back to the beginning: MoE isn’t some shiny new concept we’re trying to flex; it’s a decades-old idea that simply deserves renewed attention in a world where intelligent, resource-aware architecture design matters more than ever.
